Single-stage object detection (part 2)
Hello mọi người, tuần này mình sẽ tiếp tục phần single-stage object detection nhé. Mặc dù tui biết là tui viết mọi người cũng đi tìm paper đọc lại, nhưng thôi kệ vậy, dù sao nó cũng tạo motivations để mọi người đọc lại paper 😅
Như đã hứa, mình sẽ tìm hiểu 2 model yolo mới nhất hiện nay (và có publications) yolov4 và yolox.
Không liên quan nhưng ai đó nhận design UI cho mấy bài này giúp tui không, tui hứa sẽ hậu tạ bằng thứ mà mọi người cần nhất bây giờ: ngàn lời chúc tốt đẹp nhất trong mùa dịch này
Yolov4 (2020)
Yolov4 thật ra không phải 1 model nổi bật về architecture, về cơ bản là họ chỉ bóc tách và ghép các architecture units lại với nhau, nhưng là 1 bài paper nổi bật về việc đưa ra góc nhìn systematic về 1 architecture. Vậy nên, mình sẽ tìm hiểu họ định nghĩa lại 1 số terminology và cách để suy ra architecture yolov4
Terminology and object detector components
Đây là 1 trong số điều hay của paper này, họ define 1 model OD sẽ có cấu trúc như vầy

Lần đầu thấy cái này (thú thật là t mới thấy vài tháng trước thôi (chừa tội bài trừ YOLO nên thấy trễ)), tui kiểu: “Lạy hồn, cuối cùng cũng có người đưa ra 1 cấu trúc nhất định để mình khỏi phải lặn ngụp rồi”. Trong đây thì tuần trước mình đã điểm qua FPN và BiFPN cho phần neck, CenterNet, Yolo, RetinaNet cho phần heads, còn 1 số loại blocks ở neck mình sẽ discuss vào bài sắp tới.
Điều thứ 2 họ định nghĩa và sẽ dùng xuyên suốt bài này là 2 terminology bags of freebies và bags of specials.
- Bags of freebies được dùng để chỉ những methods mà chỉ thay đổi training strategy hoặc làm tăng
training cost nhưng không ảnh hưởng đến evaluation, development hay inference cost. Một số ví dụ về bags of
freebies có thể kể đến như:
- Data augmentation:
- To input: random erase, rotate image, cutout, MixUp, CutMix, …
- To feature map: DropOut, DropConnect, DropBlock, …
- Handling semantic distribution bias: ví dụ như class imbalance, hay những vấn đề về racist trong AI
- Bounding box regression: có thể cải thiện bằng những loại loss liên quan IoU
- Data augmentation:
- Bags of specials được dùng để chỉ những methods có khả năng tăng inference cost lên ít nhưng
bù lại tăng accuracy lên significantly. Những method này giúp enhance receptive field, thêm attention
mechanism, integrate features
- Enhance receptive field modules: enhance vùng receptive của 1 feature map bằng cách lọc đi những pixels mờ nhạt(eg: max pooling), hoặc tổng hợp thông tin của cả vùng (eg: average pooling) , ví dụ như Spatial pyramid pooling (SPP), Atrous Spatial Pyramid Pooling(ASPP) hoặc dùng max pooling như Yolov3 và những phiên bản trước đó :))
- Attention modules: như tên của nó, để enhance attention qua các layer, eg: Squeeze-and-Excitation(SE), Spatial Attention Module (SAM)
- Feature integration: khác với enhance receptive, những model này có những modules giúp tổng hợp thông tin của feature giữa các layers với nhau, chủ yếu là kết nối “low-level physical features” (pixels) với “high-level semantic feature”(context), eg: skip connection FPN, BiFPN
- Activation functions: ReLU, LReLu, PReLU, Swish, hard-Swish, Mish
Vậy là xong 2 sơ lược về cái bags, giờ thì xách bags lên mà đi đến phần architecture 🙃
Yolov4 architecture
Architecture của Yolov4 được tóm gọn lại nhiêu thôi:
- Backbone: CSPDarknet53
- Neck: SPP, PAN
- Head: Yolov3 (that’s right! v3!)
“uầy, đơn giản mà Linh, sao nãy thấy than quá trời vậy” …wait for it…

Tuy nhiên tui chỉ nói chủ yếu về architecture thôi nha.
Ở đây CSPDarknet53 hoặc CSPResNeXt50 được dùng để làm backbone khi train model dùng GPU. Bên cạnh đó, tác giả cũng có dùng 1 số backbone khác, nếu mình train VPU. Cross-stage partial connections(CSP) ra mắt năm 2019, và đi theo split and merge strategy để giảm gradient descent. Để thực hiện strategy này, CSPDarkNet53 sẽ được tách ra làm 2 nhánh, 1 nhánh sẽ có hẳn 1 DarkNet block và thực hiện tính toán như bình thường, 1 nhánh còn lại sẽ split DarkNet block thành phần nhỏ cộng với block từ layer trước đó và sẽ được train xuyên suốt quá trình. Ví dụ như hình dưới đây, mọi người có thể thấy block màu tím, chính là 1 dense block, ở layer 1 sẽ được split nhỏ ra, và compute song song với 1 dense block khác, hết quá trình, cả 2 sẽ đc merge lại, và đem đến layer 2, cứ như vậy đến layer k. CSPDarknet53 cũng tuân thủ quá trình này, nhưng với block là Darknet53 (block này đã được giới thiệu ở bài trước rồi nha mấy bạn :v)

Về phần neck, do PAN đã được nhắc đến ở bài trước, bài này tui sẽ nói về Spatial Pyramid Pooling (SPP) thôi nha. Đó giờ mình đã học 2 loại pooling layer chủ yếu: Max Pooling và Average Pooling rồi phải không? Rõ là 2 loại pooling layer đó được sử dụng rộng rãi và cũng không thay đổi mấy nếu mình dùng “either max or average”. Vậy thì thay đổi 1 loại pooling có giúp ích gì không. Câu trả lời là nếu ở Yolov4 thì mình không biết nha mấy bạn, do họ không làm Ablation study với SPP 😅. Đúng như tên gọi của nó, SPP gồm vài filters được xếp chồng lên nhau, mỗi filter này có số grid nhỏ dần bottom up (layer trên cùng có grid nhỏ nhất). Nhờ architecture như vậy, SPP có thể convert từ 1 conv sang fully connected layer mà mình không cần phải convert Conv layer sang FC bằng cách trải nó ra thành 1 vector nữa

Yolov4 còn nhiều lắm, nhưng mình chỉ bàn tới đây thôi nha mấy bạn, nếu được mọi người cứ tìm paper và đọc lại nhé. Giờ tui sẽ qua summary YoloX và mọi người (hoặc tui) sẽ có thể thở phào nhẹ nhõm :))
YoloX (2021)
YoloX là phiên bản yolo đầu tiên không dùng anchor box. Ủa rồi không dùng anchor box thì có điểm nào là Yolo, khi Yolo là dùng grid và anchor box để regress tạo ra bounding box cơ mà 🤷🏻. Anyway, về YoloX mình sẽ cần lưu ý những điểm chính như decoupled head, anchor free, và SimOTA. Tuy nhiên, anchor free họ nói khá là sơ sài, nên chắc hẹn mọi người sau. Về strong augmentation và multi positives mọi người có thể xem thêm trong paper nha.
Decoupled Head
Nếu mọi người để ý, ở model Yolo thì chỉ có 1 nhánh duy nhất để thực hiện vừa classify, vừa xem objectness, vừa làm regression. Head của Yolo series theo lẽ đó gọi là Coupled Head. Trong khi đó, những model như RetinaNet, CenterNet và EfficientDet đều có head được tẻ thành nhiều nhánh, thường là 2. Hai nhánh này sẽ là 2 submodels, mỗi submodel phụ trách 1 task riêng lẻ như classification hoặc box regression. Chỗ này khá là counter-intuitive nhỉ, làm sao có thể classify đúng được nếu ở đó regression không đúng. Nhưng YoloX chứng minh được bằng phương pháp decoupled, AP của họ đã tăng 1.1% accuracy, đồng thời giảm convergence time. Decoupled Head của YoloX gồm 1 layer convolution 1x1, theo sau đó là 2 nhánh song song có 2 conv 3x3. Do convolution layer khá nhẹ, dù có chia nhánh ra cũng không làm tăng param so với coupled head.

SimOTA
Hồi tháng 3, cũng chính nhóm này có đăng 1 bài về Optimal Transport Assignment(OTA), và giờ họ tinh giản phương pháp đó để đưa vào paper về YoloX này. Có lẽ sau nhiều lần tìm hiểu về model thì mình cũng đã thấy được nhiều nhược điểm của việc assign label cho các object của các model, bởi những object này vừa có những shape và size khác nhau, vừa có thể trùng nhau gây nhiễu đến boundary.
Để giải quyết vấn đề này, rất nhiều thuật toán để assign label dynamically đã được phát triển, và OTA là 1 trong những thuật toán đó (và tui phải đọc thêm 1 bài paper). Optimal Transport là 1 problem phổ biên trong Optimization Theory, bài toán này được phát nguồn từ việc muốn vận chuyển các đơn hàng homogeneous từ supplier \(x\) đến demander \(y\) mình sẽ phải tốn 1 cost là \(c(x,y)\). Một đơn hàng có điều kiện không được split, tức là đơn hàng không thể chia cho nhiều bên để vận chuyển, và một supplier phải luôn giao hàng cho đúng một demander. Nói cách khác, giữa 1 supplier và 1 demander tồn tại 1 mối quan hệ \(1-1\) và tổng supply phải bằng tổng demand. Vậy nếu có nhiều supplier và nhiều demander, mình sẽ có 1 plan gọi là transportation plan \(T\) thỏa mãn \(T: X \rightarrow Y\) là 1 song ánh, và để có được 1 điểm \(y\) tương ứng với \(x\) mình sẽ biểu diễn bằng \(y=T(x)\). Bài toán Optimal Transport là bài toán tìm ra được optimal transportation plan sao cho tổng cost trên plan này là thấp nhất trong tất cả các transportation plan, và ở đây mình sẽ có thêm 1 vấn đề nữa: làm sao để assign agents và tasks để có được kết quả tối ưu này. Tổng cost của các plan được biểu diễn bằng công thức: \[c(T)=\sum_{x \in X}c(x,T(x))\]
Vậy thì từ đây, họ mới tạo 1 mối liên hệ. Giả sử mình xem ground truth là supplier và kết quả predict box (trong paper gọi là 1 anchor) là demander, mình cũng sẽ có cost xuất hiện giữa supplier và demander, đó chính là loss function mà mình thường gặp, chính là weighted sum giữa class loss và regression loss. \[c_{ij}=L^{cls}_{ij}+\lambda L^{reg}_{ij}\] Bài toán của mình sẽ trở thành label cần được assign như thể nào để đạt được optimal transport cost. Đến đây thì mọi người sẽ thắc mắc:“Ủa đó giờ không phải tụi mình cũng làm vậy sao” … Ừ thì giờ mình đến phần khác đây. Trước kia đa phần các model khi xét anchor box hay anchor points thì đa phần dùng IoU threshold hoặc 1 loại loss nào đó để xem objectness của anchor box đó đúng không? Ví dụ nếu IoU giữa predicted và ground truth >0.5, mình sẽ xem ở đó có 1 object, rồi tính loss, và cứ từ đó lấy đạo hàm để update weights, hoặc là sẽ dùng NMS để tìm ra box hợp lý nhất. Tuy nhiên, ở phương pháp này, mình sẽ không cần phải xét threshold, mà sẽ lưu lại hết các loss giữa các ground truth và anchor thành 1 matrix, khi này mình đã có 1 transportation plan. Theo như bài báo gốc thì mình sẽ cho plan này chạy qua Sinkhorn-Knopp Iteration để đưa ra được 1 optimal assigning plan.
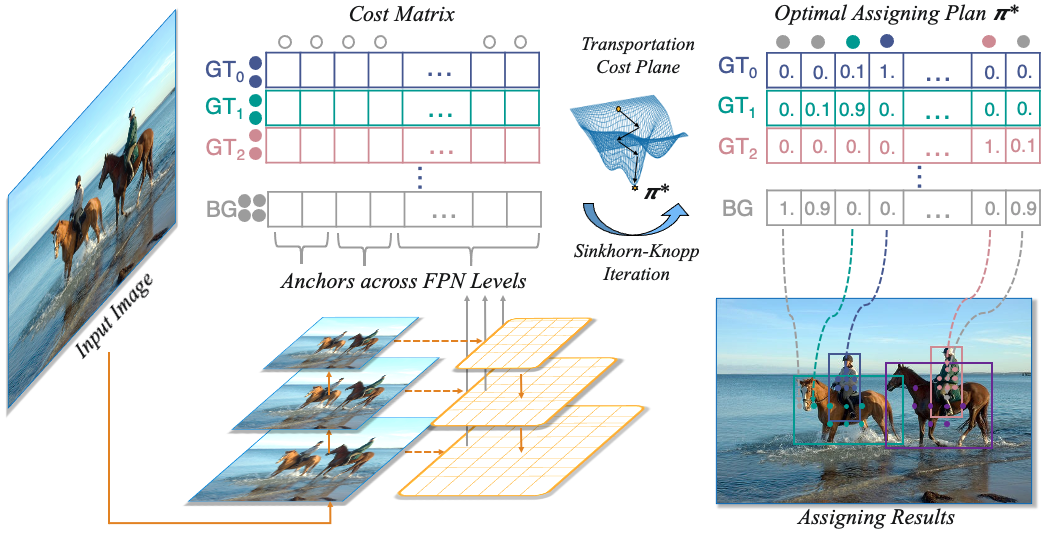
Uầy, vầy thì không phải cũng tốn kém quá sao? Thay vì vậy phương pháp cũ mình chỉ cần xét threshold thôi mà. Không nhé, ở phương pháp cũ mình xét label một cách tĩnh, tức là “ừ thôi cứ assign vậy đi, rồi máy nó học rồi update từ từ” và trong quá trình học đó, mình không biết nó đã học sai bao nhiêu cái rồi, vậy thì sao không chỉ nó chỗ đúng cho nó học cho nhanh. Thực tế, OTA đã giúp cải thiện training time. Và dĩ nhiên, sau khi assign được label với optimal transportation plan, loss function vẫn phải được tính đạo hàm để update lại weight (backprop), và mình sẽ bắt đầu iteration (iteration của training, không phải của Sinkhorn-Knopp nha) mới.
Ở YoloX, Sinkhorn-Knopp đã được thay bằng Dynamic \(k\) Estimation để tăng training time, tuy nhiên general strategy không thay đổi.
Backbone Model
YoloX sử dụng DarkNet53 của Yolov3 gọi là YoloX-DarkNet53 và Modified CSP của Yolov5 gồm 3 models YoloX-M, YoloX-L, và YoloX-X. Trong các model thuộc family của YoloX, YoloX-X đạt được kết quả mAP tốt nhất, nhưng cũng là model chậm nhất, YoloX-M thì thôi khỏi nói, chậm hơn YoloX-DarkNet53 và mAP cũng thấp hơn 🙃 . Vậy nên cách tốt nhất là mình sẽ thay 1 số layer của DarkNet53 thành Lambda layer, và có thể đánh giá thêm với Yolov3 và v4 luôn.

Vậy là mình đã xong 2 model Yolo gần đây nhất. Tạm thời thì tài liệu về những phần liên quan object detection cũng được kha khá rồi, và mình cũng đã định hướng được hướng đi như thế nào, nên chắc tui sẽ không viết bài về units như đã nói, thay vào đó sẽ tập trung giải quyết cái lambda layers và phần loss functions. Cảm ơn mọi người đã đọc. Cố lên mọi người ơi 🔥🔥🔥